

2016年,围棋人工智能软件AlphaGo打败了韩国围棋名将李世石。2017年,新一代AlphaGo(AlphaGo Master)的战斗力升级,又打败了世界排名第一的柯洁。这样的人工智能(Artificial Intelligence)系统,不再简单地只靠储存能力战胜人类,而是已经在一些具体的领域超越了人类的认知,甚至像是拥有了“思考”的能力,更接近大众对人工智能的想象。
人工智能似乎一直是一个遥远的科幻的概念,但事实上,当今世界很多应用已经达到了“人工智能”的标准。除了前文提到的围棋软件,还有自动驾驶系统、智能管家,甚至苹果手机上的语音助手Siri都是一种人工智能。而这些应用背后的核心算法就是深度学习(Deep Learning),这也是机器学习(Machine Learning)领域最火热的一个分支。和其他机器学习算法有很大不同,深度学习依赖大量数据的迭代训练,进而发现数据中内在的特征(Feature),然后给出结果。这些特征中,有很多已经超越了人为定义的特征的表达能力,因此得以让深度学习在很多任务的表现上大大超越了其他机器学习算法,甚至超越了人类自己。
但是,深度学习还没能全方面超越人类。相反,它的工作完全依赖于人类对算法的设计。深度学习从诞生到爆发用了大约五十年。从其发展历程,我们可以窥见计算机科学家们的步步巧思,并从中探讨其可能的发展方向。
一、什么是深度学习
深度学习就是人工神经网络(Artificial Neural Network)。神经网络算法得名于其对于动物神经元传递信息方式的模拟,而深度学习这一“俗称”又来自于多层级联的神经元:众多的层让信息的传递实现了“深度”。
在动物身上,神经一端连接感受器,另一端连接大脑皮层,中间通过多层神经元传导信号。神经元之间也不是一对一连接,而是有多种连接方式(如辐射式、聚合式等),从而形成了网络结构。这一丰富的结构最终不仅实现了信息的提取,也使动物大脑产生了相应的认知。动物的学习过程则需要外界信息在大脑中的整合。外界信息进入神经系统,进而成为大脑皮层可以接收的信号;信号与脑中的已有信息进行比对,也就在脑中建立了完整的认知。
类似地,通过计算机编程,计算机科学家让一层包含参数(Parameter)和权重(Weight)的函数模拟神经元内部的操作,用非线性运算的叠加模拟神经元之间的连接,最终实现对信息的重新整合,进而输出分类或预测的结果。针对神经网络输出结果与真实结果之间的差异,神经网络会通过梯度(Gradient)逐层调整相应的权重以缩小差异,从而达到深度学习的目的。
二、深度学习的雏形
其实,模拟动物的神经活动,并非深度学习的专利。早在1957年,Frank Rosenblatt就提出了感知机(Perceptron)的概念。这是一种只能分出两类结果的单层神经网络。这种模型非常简单,输出结果与输入信息之间几乎就是一个“加权和”的关系。虽然权重会直接根据输出结果与真实值之间的差异自动调整,但是整个系统的学习能力有限,只能用于简单的数据拟合。
几乎与此同时,神经科学界出现了重大进展。神经科学家David Hubel和Torsten Wiesel对猫的视觉神经系统的研究证实,视觉特征在大脑皮层的反应是通过不同的细胞达成的。其中,简单细胞(Simple Cell)感知光照信息,复杂细胞(Complex Cell)感知运动信息。
受此启发,1980年,日本学者福岛邦彦(Kunihiko Fukushima)提出了一个网络模型“神经认知机(Neocognitron)”(图1)用以识别手写数字。这种网络分成多层,每层由一种神经元组成。在网络内部,两种神经元交替出现,分别用以提取图形信息和组合图形信息。这两种神经元到后来演化成了重要的卷积层(Convolution Layer)和提取层(Pooling Layer)。但是这个网络的神经元都是由人工设计而成,其神经元也不会根据结果进行自动调整,因此也就不具有学习能力,只能限制在识别少量简单数字的初级阶段。
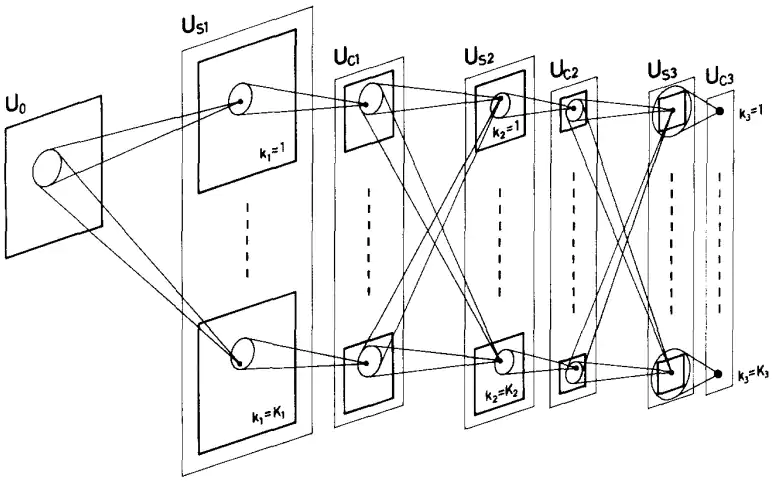
当学习能力无法被实现的时候,就需要更多的人工设计来替代网络的自主学习。1982年,美国科学家John Hopfield发明了一种神经网络,在其中加入了诸多限制,让神经网络在变化中保持记忆以便学习。同年,芬兰科学家Teuvo Kohonen在无监督算法向量量化神经网络(Learning Vector Quantization Network)的基础上提出了自组织映射(Self-Organizing Map),希望通过缩短输入和输出之间的欧氏距离,从繁杂的网络中学习到正确的关系。1987年,美国科学家Stephen Grossberg和Gail Carpenter依据自己早先的理论提出了自适应共振理论网络(Adaptive resonance theory),也就是让某个已知信息和未知信息发生“共振”,从而从已知信息推测未知的信息,实现“类比学习”。虽然这些网络都加上了“自组织”、“自适应”、“记忆”等关键词,但其学习方式效率不高,而且需要根据应用本身不断地优化设计,再加上网络的记忆容量很小,很难在实际中应用。
1986年,计算机科学家David Rumelhart、Geoffrey Hinton和Ronald Williams发表了反向传播算法(Backpropagation),才算阶段性地解决了神经网络学习的难题。通过梯度的链式法则,神经网络的输出结果和真实值之间的差异可以通过梯度反馈到每一层的权重中,也就让每一层函数都类似感知机那样得到了训练。这是Geoffrey Hinton第一个里程碑式的工作。如今的他是Google的工程研究员,曾获得计算机领域最高荣誉的图灵(Turing)奖。他曾在采访中说:“我们并不想构建一个模型来模拟大脑的运行方式。我们会观察大脑,同时会想,既然大脑的工作模式可行,那么如果我们想创造一些其他可行的模型,就应该从大脑中寻找灵感。反向传播算法模拟的正是大脑的反馈机制。
之后的1994年,计算机科学家Yann LeCun在Geoffrey Hinton组内做博士后期间,结合神经认知机和反向传播算法,提出了用于识别手写邮政编码的卷积神经网络LeNet,获得了99%的自动识别率,并且可以处理几乎任意的手写形式。这一算法在当时取得了巨大的成功,并被应用于美国邮政系统中。
三、深度学习的爆发
尽管如此,深度学习并没有因此而热门。原因之一,就是神经网络需要更新大量参数(仅2012年提出的AlexNet就需要65万个神经元和6000万个参数),需要强大的数据和算力的支持(图2)。而如果想通过降低网络的层数来降低数据量和训练时间,其效果也就不如其他的机器学习方法(比如2000年前后大行其道的支持向量机,Support Vector Machine)。2006年Geoffrey Hinton的另一篇论文首度使用了“深度网络”的名称(Deep Belief Nets),为整个神经网络的优化提供了途径。虽然为后面深度学习的炙手可热奠定了基础,但是之所以用“深度网络”而避开之前“神经网络”的名字,就是因为主流研究已经不认可“神经网络”,甚至到了看见相关标题就拒收论文的程度。
深度学习的转折发生在2012年。在计算机视觉领域,科学家也逐渐注意到了数据规模的重要性。2010年,斯坦福大学的计算机系副教授李飞飞(Li Fei-Fei)发布了图像数据库ImageNet,共包含上千万张经过人工标记过的图片,分属于1000个类别,涵盖动物、植物、生活等方方面面。2010—2017年,计算机视觉领域每年都会举行基于这些图片的分类竞赛,ImageNet也因此成为全世界视觉领域机器学习和深度学习算法的试金石。2012年,Geoffrey Hinton在多伦多大学的学生,Alex Krizhevsky,在ImageNet的分类竞赛中,通过在两块NVIDIA显卡(GPU)上编写神经网络算法而获得了冠军,而且其算法的识别率大幅超过第二名。这个网络随后被命名为AlexNet。这是深度学习腾飞的开始。
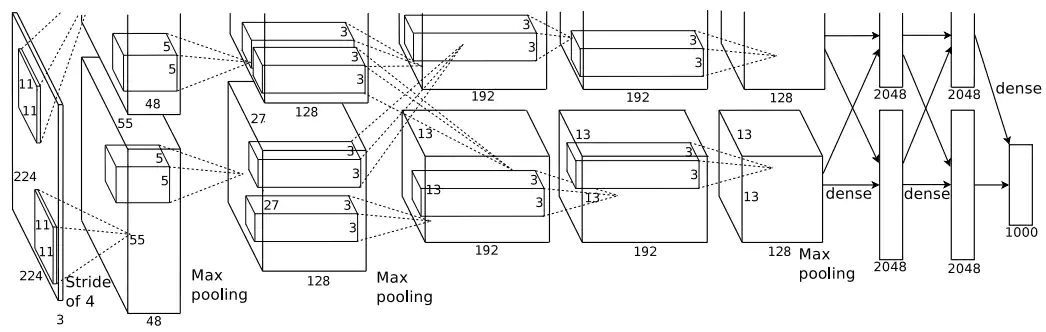
从AlexNet开始,由ImageNet提供数据支持,由显卡提供算力支持,大量关于神经网络结构的研究逐渐铺开。首先,由于大量软件包的发布(如Caffe,TensorFlow,Torch等),实现深度学习变得越来越容易。其次,在研究领域,从ImageNet分类竞赛和任务为更加复杂的图像分割和描述的COCO竞赛中,又产生了VGGNet、GoogLeNet、ResNet和DenseNet。这些神经网络的层数逐渐增加,从AlexNet的11层到VGGNet的19层,而到ResNet和DenseNet时,深度已经达到了150层乃至200层,达成了名副其实的“深度”学习。这些深度神经网络在一些数据集上关于分类问题的测试,甚至已经超过了人类的识别准确率(在ImageNet上人类的错误率大约为5%,而SENet的错误率可以达到2.25%)。如表1所示:

自此,计算机科学家们越来越多地利用神经网络算法来解决问题。除了上述在二维图像上的分类、分割、检测等方面的应用,神经网络还被用在时序信号甚至是无监督的机器学习中。循环神经网络(Recurrent Neural Network)可以按照时间顺序接受信号的输入。一方面,它的每层神经元可以压缩并储存记忆;另一方面,它可以从记忆中提取有效的维度进行语音识别和文字理解。而把神经网络用在无监督学习上,就跳出了“提取主成分”或者“提取特征值”的窠臼,简单地用一个包含了多层网络的自编码器(Autoencoder),就可以把原始信息自动地实现降维和提取。再结合向量量化网络,可以实现对特征的聚类,进而在没有太多标记数据的情况下得到分类结果。可以说,神经网络无论是效果还是应用范围上,都成为了无可争议的王者。
四、深度学习的发展现状和趋势
2017年,ImageNet图像分类竞赛宣布完成了最后一届,但这并不意味着深度学习偃旗息鼓。恰恰相反,深度学习的研究和应用脱离了之前以“分类问题”为研究主题的阶段,进入了广泛发展的阶段。同时,与深度学习相关的国际会议投稿量逐年呈指数式地增加,也说明有越来越多的研究者和工程师投身于深度学习算法的研发和应用。笔者认为,深度学习近年来的发展呈现出以下几个趋势。
第一,从结构上看,神经网络的类型会变得更加多样。其中,可以执行卷积神经网络逆向过程的生成对抗网络(Generative Adversarial Network)从2016年被提出以来发展迅速,成为了深度学习一个重要的“增长点”。由于深度学习算法可以从原始信息(如图像)中提取特征,那么其逆过程逻辑上也是可行的,即利用一些杂乱的信号通过特定神经网络来生成相应的图像。于是,计算机科学家Ian Good fellow提出了生成对抗网络。这个网络除了能生成图像的生成器(Generator)之外,还提供了一个判别器(Discriminator)。在训练过程中,生成器趋于学习出一个让计算机难以分辨的、极度逼近真实的生成图片,判别器趋于学习出强大的判定真实图片和生成图片的能力。二者对抗学习,生成图片做得越真实,判别器就会越难分辨;判别器能力越强,也就促使生成器生成新的、更加真实的图片。生成对抗网络在人脸生成和识别、图像分辨率提升、视频帧率提升、图像风格迁移等领域中都有着广泛的应用。
第二,研究的问题趋于多样。一方面,一些在机器学习其他分支中的概念,如强化学习(Reinforcement Learning)、迁移学习(Transfer Learning),在深度学习中找到了新的位置。另一方面,深度学习本身的研究也从“工程试错”向“理论推导”发展。深度学习一直因其缺少理论基础而饱受诟病,在训练过程中几乎完全依赖数据科学家的经验。为了减少经验对结果的影响,以及减少选择超参数的时间,除了对最初经典网络结构的修改,研究者们也在从根本上修正深度学习的效率。一些研究者在试图联系其他机器学习的方法(比如压缩感知、贝叶斯理论等),用以使深度学习从工程的试错变为有理论指导下的实践。还有一些研究在试图解释深度学习算法的有效性,而不只是把整个网络当做一个黑盒子。与此同时,研究者也在针对超参数建立另一个机器学习的问题,即元学习(meta Learning),以降低选择超参数过程的难度和随机性。
第三,随着大量研究成果的新鲜出炉,更多的算法也被应用于产品中。除了一些小规模的公司陆续开发了图像生成小程序,大公司们也在竞相抢占深度学习这一高地。互联网巨头Google、Facebook和Microsoft都先后成立了深度学习的发展中心,中国的互联网公司百度、阿里巴巴、腾讯、京东以及字节跳动等也都各自成立了自己的深度学习研究中心。一些基于深度学习技术的独角兽公司,如DeepMind、商汤、旷视等,也从大量竞争者中脱颖而出。2019年以来,产业界的深度学习研究也渐渐地从关注论文发表转变到了落地的项目。比如腾讯AI Lab对视频播放进行优化,比如依图制作的肺结节筛查已经在国内的一些医院试点。
第四,随着5G技术的逐渐普及,深度学习会跟云计算一起嵌入日常生活。深度学习这项技术一直难以落地的原因是计算资源的匮乏。一台配备合适显卡的超级计算机的成本可以达到50万人民币,而并不是所有公司都有充足的资金和能够充分使用这些设备的人才。而随着5G技术的普及,以及云技术的加持,公司可以通过租用的方式,低成本地从云中直接获得计算资源。公司可以将数据上传到云端,并且几乎实时地收到云端传回的计算结果。一大批新兴的创业公司正在想办法利用这些基础设施:他们召集了一批计算机科学家和数据科学家,为其他公司提供深度学习算法支持和硬件支持。这使得一些之前跟计算机技术关系不大的行业(比如制造业、服务业、娱乐业,甚至法律行业),不再需要自己定义问题、研发方案,而是通过与算法公司合作便利地享受到计算机技术行业的专业支持,也因此更容易获得深度学习的赋能。
五、总结与讨论
在五十多年的历程中,深度学习经过了从雏形到成熟、从简单到复杂的发展,在学术界和业界积累了大量理论和技术。现在,深度学习的发展方向趋向于多元化。这一方面是因为大量产品正处于研发阶段,另一方面计算机科学家也在做一些关于深度学习的更加细致的研究。
当然,作为一个综合性的学科,除了以图像识别为核心的发展历程,深度学习在语音分析和自然语言处理上也有其各自的发展过程。同时,多种神经网络、多媒体形态的结合,正在成为研究的热点。比如结合图像和语言处理的自动给图片配字幕(Image Captioning)就是一个具有挑战的课题。
需要指出的是,神经网络的实现并非只有上述这一种方法,一些现阶段没有得到广泛使用的网络结构,比如自适应共振理论网络、Hopfield网络以及受限玻尔兹曼机(Restricted Boltzmann Machine)也可能在未来提供整个行业的前行动力。可以肯定,虽然现在深度学习还是一个似乎萦绕着高级和神秘光环的存在,但在不久的将来,这件超级武器将会成为大小公司的基本技术。

王东昂是悉尼大学在读博士。他的研究领域涉及了医学图像、人工智能、神经科学、视频分析等多个领域,并致力于在实际系统中应用人工智能技术。他曾在CVPR、ECCV等国际会议中发表过论文,并受邀长期为IEEE Transactions on Circuits and Systems for Video Technology、IEEE Transactions on Multimedia等学术杂志和ICML、AAAI等国际会议审稿。他在机器学习和计算机视觉领域有超过5年的开发经验,曾与中国、美国、澳大利亚的多家公司和机构合作开发项目,其中包括多角度视频中的行为识别、基于道路监控的路况预测和自动化脑CT筛查系统。
该发布文章为贸泽独家原创文章,转载请注明来源。对于未经许可的复制和不符合要求的转载我们将保留依法追究法律责任的权利。

